Jak już wspominałem przy okazji posta z serii Pokaż kod, pisząc Speechlist, na początku byłem nastawiony na rozwiązywanie testów głosem. Częściowo mi się to udało, chociaż przeniesienie tego na telefon nie było łatwe, żeby nie powiedzieć – sprawiało kłopoty, dlatego finalnie je porzuciłem na rzecz zwykłego wstawiania tekstu dotykiem. Zostałem z częściowo już napisanym frontendem pod rozpoznawanie głosu, możecie go zobaczyć w działaniu tutaj:
Kod Speechlist udostępniłem za darmo pod adresem: https://bitbucket.org/dbeef/speechlist
Nie rozpisałem się wtedy co do samego Sphinxa, a to jest temat na większy post.
Czym jest CMUSphinx
CMUSphinx jest opensourcowym narzędziem do rozpoznawania mowy, wspierające C, C++, C#, Python, Ruby, Java, Javascript i rozpoznające m.in. angielski, francuski i niemiecki (chociaż społeczność zbudowała modele rozpoznające także chociażby rosyjski, lista modeli do pobrania jest tutaj).
Wielkim plusem w stosunku chociażby do androidowych usług rozpoznawnia głosu (komunikujących się z serwerami Google) z których można korzystać pisząc aplikacje jest to, że Sphinx działa całkowicie offline.
Do jego działania potrzebne są 3 pliki: acoustic model, dictionary i language model.
Acoustic model zależy od języka i sami go raczej nie stworzymy, pobieramy gotowy z listy którą zamieściłem wyżej. Przykładowo, dla języka angielskiego pobieramy model en-us.
Language model i dictionary generujemy sami za pomocą narzędzi do których odniosę się później, ale można je także pobrać.
Teraz najważniejsze: aby uzyskać niemal 100% skuteczność rozpoznawania, jak na filmiku wyżej, nie używałem gotowego słownika i modelu językowego z ich strony (zawierającego wszystkie słowa). CMUSphinx udostępnia narzędzie, pozwalające zbudować słownik tylko konkretnych słów:
http://www.speech.cs.cmu.edu/tools/lextool.html
Dzięki temu, że zamieściłem tam tylko te słowa, które muszą być rozpoznane w Speechlistowym teście, poprawność była tak dobra, że trudno uwierzyć.
Przy tym wszystkim warto też dodać, jak niewiele zasobów wymaga Sphinx. Słowniki i modele ważą tyle co nic, a działanie nie wymaga dużej mocy od komputera.
PocketSphinx z którego korzystam na filmiku i w kodzie poniżej, waży 6.7 kB!
https://bitbucket.org/dbeef/speechlist/src/990c18c459d5f6b89971fc6b93d24fa4730ba07f/android/libs/pocketsphinx.jar?at=master&fileviewer=file-view-default
Praktyka
Wykorzystanie Sphinxa w przykładzie z filmiku wygląda następująco:
Tworzymy obiekt edu.cmu.sphinx.api.Configuration, aby załadować z plików modele i słowniki.

Tworzymy obiekt edu.cmu.sphinx.api.LiveSpeechRecognizer, dostarczamy mu konfigurację w konstruktorze i stawiamy warunek który skończy rozpoznawanie mowy (np. while(!lastRecognizedWord.equals(“apple“)), w poniższym przykładzie rozpoznawanie trwa przez cały czas (while(true)).

To wszystko. Teraz, we frontendowej części kodu odczytujemy zapisane przez Sphinx słowa i wyświetlamy na ekranie:
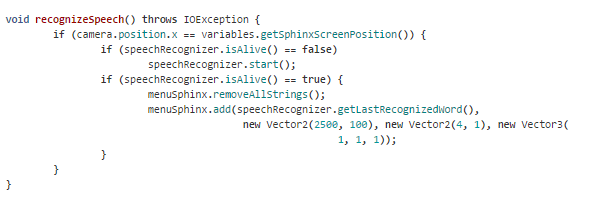
Cały plik znajduje się pod adresem:
https://bitbucket.org/dbeef/speechlist/src/990c18c459d5f6b89971fc6b93d24fa4730ba07f/core/src/com/dbeef/speechlist/recognition/SpeechRecognizer.java?at=master&fileviewer=file-view-default
Linki:
Repozytorium Speechlist (branch master jest pod rozpoznawanie mowy):
https://bitbucket.org/dbeef/speechlist/src/990c18c459d5?at=master
Artykuł opisujący dostosowywanie CMU pod język polski:
Dla szukających więcej informacji na temat słowników:
https://cmusphinx.github.io/wiki/tutorialdict/
Mam jednak zastrzeżenie co do ich słów:
There is no need to remove unused words from the dictionary unless you want to save memory, extra words in the dictionary do not affect accuracy.
Z moich doświadczeń wynika, że jest zupełnie odwrotnie. Przekonajcie się sami, zapiszcie sobie kilka słów na kartce, które chcecie wypróbować na Sphinxie, pobierzcie cały słownik z ich strony, wypróbujcie dokładność, a potem zróbcie to samo generując własny za pomocą ich narzędzia, ale wstawiając do niego tylko te słowa, które potem będziecie wymawiać.

 Mając wtyczkę, podaję ścieżkę do niej w kodzie. Teraz musimy jeszcze pobrać
Mając wtyczkę, podaję ścieżkę do niej w kodzie. Teraz musimy jeszcze pobrać 

 Źródło:
Źródło:  Przykład – Tabela znaczników dla formatu JPG – Źródło:
Przykład – Tabela znaczników dla formatu JPG – Źródło:  Źródło:
Źródło:  To praktycznie cały kod, pominąłem obsługę argumentów z konsoli i wczytanie pliku. Zostawiłem również możliwość włączenia w trybie podmieniającym bajty w dowolnym miejscu tablicy, dla różnorodności (co jasne, wygeneruje to więcej błędnych plików).
To praktycznie cały kod, pominąłem obsługę argumentów z konsoli i wczytanie pliku. Zostawiłem również możliwość włączenia w trybie podmieniającym bajty w dowolnym miejscu tablicy, dla różnorodności (co jasne, wygeneruje to więcej błędnych plików).






 Całość dostępna jest na
Całość dostępna jest na 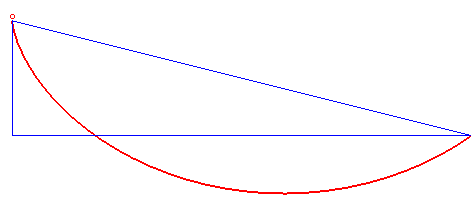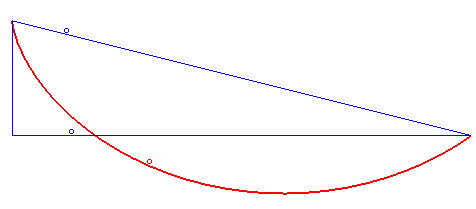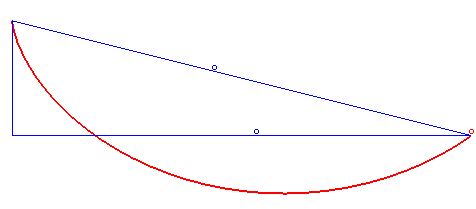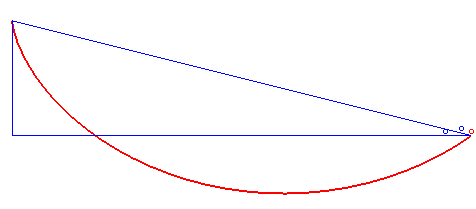
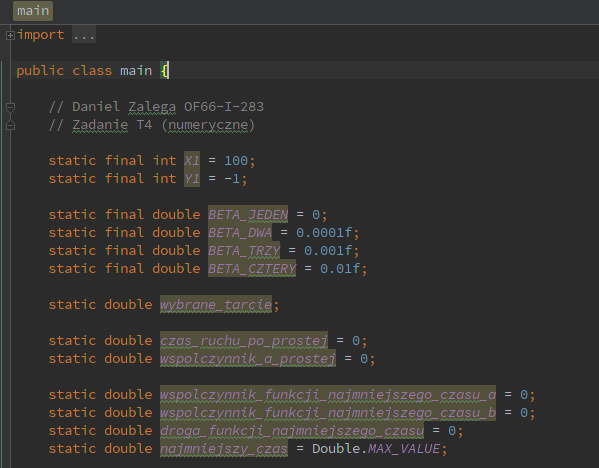
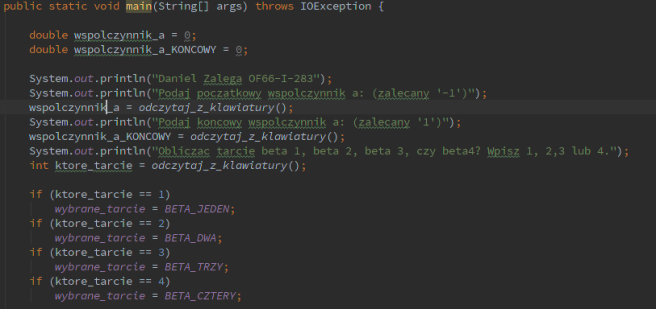 Po przyjęciu danych, przechodzę do pętli która iteruje od współczynnika początkowego do końcowego, dodając przy każdym przejściu bardzo małą deltę – 0.001. Dobieram następnie do otrzymanego tak współczynnika ‘a’ pozostałe współczynniki (współczynnik c jest zawsze zerowy). Warte podkreślenia jest, że sprawdzam, czy mam do czynienia z funkcją liniową (a = 0) nie poprzez operator porównania, a dopisaną przeze mnie funkcją – robię to, ze względu na to, że komputery mają kłopoty z reprezentowaniem ułamków binarnie (binarny to w ogóle słaby system na ułamki), odsyłam zaciekawionych poniżej:
Po przyjęciu danych, przechodzę do pętli która iteruje od współczynnika początkowego do końcowego, dodając przy każdym przejściu bardzo małą deltę – 0.001. Dobieram następnie do otrzymanego tak współczynnika ‘a’ pozostałe współczynniki (współczynnik c jest zawsze zerowy). Warte podkreślenia jest, że sprawdzam, czy mam do czynienia z funkcją liniową (a = 0) nie poprzez operator porównania, a dopisaną przeze mnie funkcją – robię to, ze względu na to, że komputery mają kłopoty z reprezentowaniem ułamków binarnie (binarny to w ogóle słaby system na ułamki), odsyłam zaciekawionych poniżej: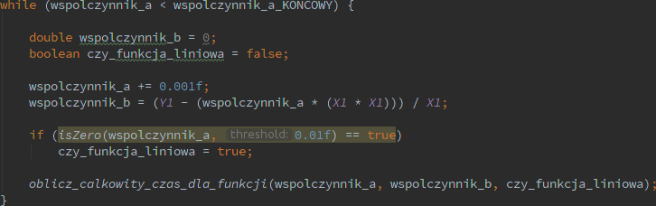 Wspomniana pętla while.
Wspomniana pętla while.

{kind=link}
You must be logged in to post a comment.