
Intro
Ever since reading Multiplayer Game Programming by Glazer & Madhav I was toying with an idea of taking some classic multiplayer game, simulating a set of typical network problems and recording how/if the game mitigates them, possibly witnessing tricks as described by the book. At the forefront of my experiment – my childhood’s favorite – Soldat.
Setup

- Using 2 separate computers over LAN
- Hosting Soldat server on the same computer as the reference Soldat client
- Using Clumsy to simulate network issues on computer B
- Every tested network issue, be it lag or packet dropping, has been applied on both inbound and outbound packets to/from computer B
- For exact parameters (lag delay in ms, packet drop chance, etc.) see the screenshot below:

Latency hiding tricks
Client side move prediction and dead reckoning

in/out lag, 300ms
The client, instead of waiting for the server to send back updated position after pressing A (move left) key, implements move prediction. Player feels an instant feedback after his key press, even though his input is effectively sent only after a 300 ms delay.
Take two things out of this recording: the discrepancy between both views – from the reference client’s perspective, the other player is still standing while the other thinks he’s moving – and instantness of the character movement from the lagging client perspective.

in/out lag, 300ms
That being said, the server always has the final word, so called authority. Recording above depicts an attempt to pick up a “berserk mode” crate by both clients standing within the same distance starting at the same time. Notice how the lagging client does not get the crate, even though from his perspective he was the one to pick up the crate first.

in/out packet drop, 50% chance
Also, prediction is just prediction – if packets are dropped, and in fast-paced games there’s little reason to resend them, as they will be out of date the moment you realise delivery failed – then the other party keeps updating their simulation based on the last received information (so called dead reckoning). Here, discrepancy appears as the client dropped a packet informing the server that he stopped pressing the key. Once the packet-dropping client presses a jump button, the server realises his mistake and teleports the client where he should be (at least according to the server, because remember, server has the authority).
Minor detail: notice how the idle animation is running only on the reference client. Could be a matter of a dropped packet, but it hints another lesson: save the bandwidth, don’t waste packets for sending information that is irrelevant for the gameplay. You will notice that particle effects differ on both clients as well.

in/out packet drop, 50% chance
Since packets are dropped for both in/out, the packet-dropping client also has to resolve client-server discrepancies that arise. The information he gets on other players’ movement is less frequent in this scenario. Notice how it teleports players to their true (server) position once a packet finally gets through. Marcinkowski makes a point on his blog about how this process should be smoothened, so it’s less visible for the player when it happens. One possible idea is to interpolate the discrepancy-position-fix over a few frames to make it less teleport-like.

in/out packet throttling, 30% chance, 500ms timeframe
Similarly to packet drop, throttling packets makes the same effect. Per Clumsy documentation:
Throttle: block traffic for a given time frame, then send them in a single batch.
…which in turn causes discrepancies for the client to resolve – because remember, only the most recent packet is of value, and if we receive a single batch of packets from the past 500ms, effectively it’s the same experience as packet dropping, because majority of this data can be dropped (they are stale packets).
Server-side rewind

in/out lag, 300ms
One of the tricks Glazer & Madhav describe is so called server-side rewind, a lag-compensation technique. It’s about making hit detection fair, despite differences in client latency. The server determines whether a shot fired by a lagging-client should hit based on what he saw at the time they fired, not what the server sees now. I did not record this exact scenario per-se, but still witnessed something unusual – notice how the server decided to spawn a projectile after the lagging-player died (reference client view). I’m sure some kind of a lag-compensation technique was employed here.
Handling out-of-order packets

in/out out-of-order, 60% chance
Look closely. Do you see anything special? Me neither, that’s because Soldat handles out of order packets well. To quote Marcinkowski’s own words:
Typically you just number the packets and discard any packets out of order. This is where packet loss really occurs, when you lose them yourself because they came out of order or late. So the time spent on making LD work with packet loss was not wasted. I spent an entire month before releasing the alpha trying every solution under the sun to make the multiplayer smooth in Link-Dead and the results are very good.
Securing against malicious activity
Flooding
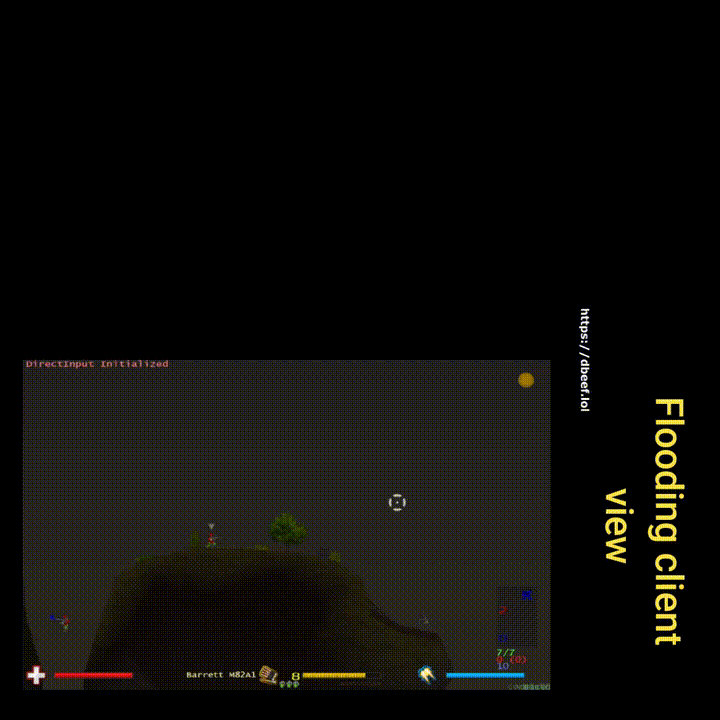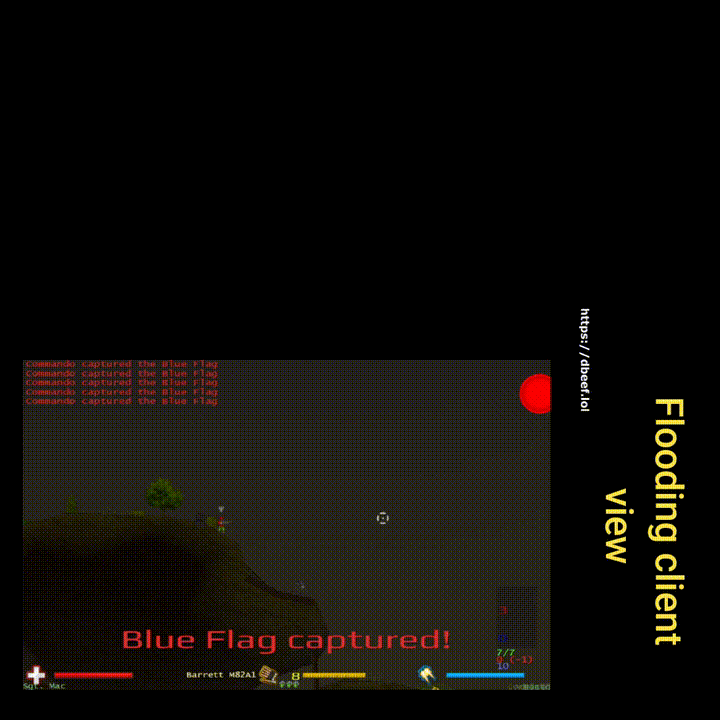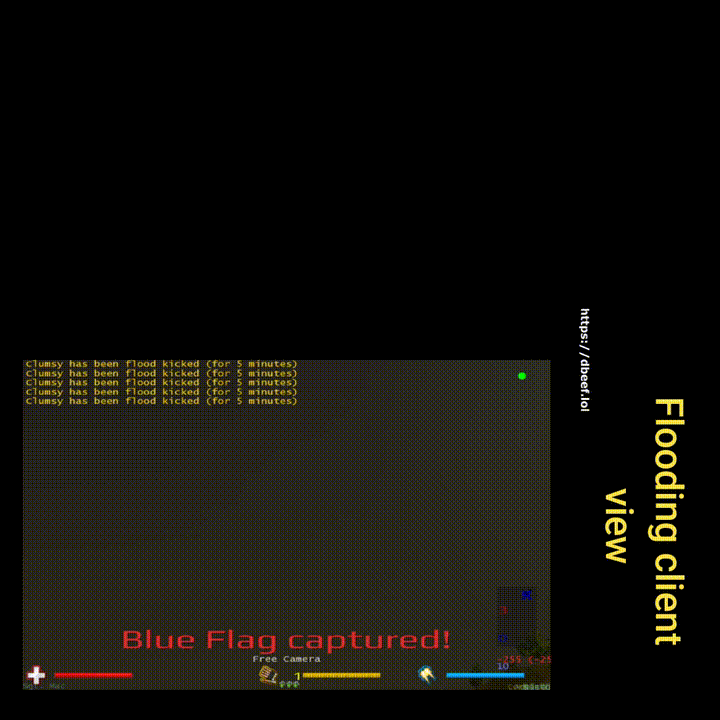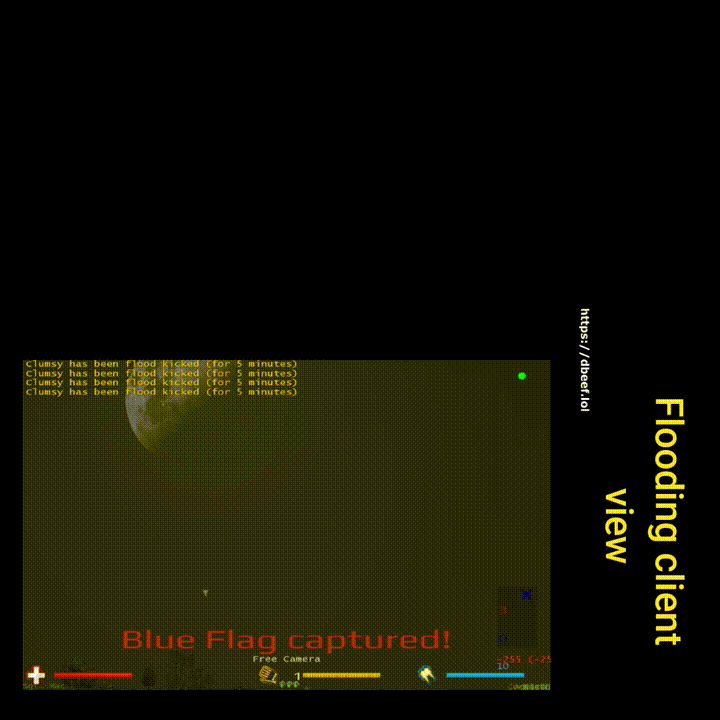
in/out duplicate, count of 20, 100% chance
For the context: I increased both the count and chance iteratively. The server would tolerate a lot and only an extreme value of duplicating every packet 20 times would cause the server to ban the duplicating-client. Why does the server not ban after the first duplicated packet? One idea is – because it can happen even without malicious intentions. Given some kind of a packet resend mechanism is implemented and the client is not acknowledged in time that the packet has been received (acknowledgment-packet could be dropped, lagged, etc.), it could send the packet again. Just speculating, much simpler and more realistic would be that there’s a fixed rate of maximum packets per client per unit of time – which would be more suiting for a fast paced game than resending.
As a funny side note, notice how the chat messages are duplicated as well. This is likely because both inbound and outbound packets are set to be duplicated.
Summary
Simply – kudos to MM for creating lots of good memories and a game that is hardened against even a very hostile network environment.
This experiment pictures how two distinctive players can have two, very different perceptions of what’s happening in the game and it’s a compromise we all agree for the game to be smooth and fun. With every client having his own version of the simulation, the only source of truth is the authoritative server, and every client is just doing its best to align his own simulation with it.










 DVDLiveWallpaper – Just what you see.
DVDLiveWallpaper – Just what you see.


You must be logged in to post a comment.