Ostatnia część, w której będę skupiał się na modemie. Następne części będą już skupiały się na praktycznym zastosowaniu, tj. będziemy pisać turową grę multiplayer, którą obsłuży nasz modem. Jakiekolwiek zmiany w backendzie (modem) będą pisane adhoc, bez specjalnych postów. Zapraszam.
Na czym skończyliśmy
Ostatni post zakończyliśmy 3 problemami do rozwiązania:
- Dostęp do głośników realizowany w jak najkrótszym czasie, bez błędu dostępu który pojawia się co jakiś czas (java.lang.IllegalStateException: Mixer is already open, tj. program próbuje odtworzyć nowy dźwięk, zanim obiekt zakończy odtwarzanie poprzedniego).
- Weryfikacja poprawności przesyłu danych – metoda która pozwoli stwierdzić, czy pakiet informacji przesłano bez przekłamań
- Opracowanie sposobu na szybkie przesyłanie jsonów, tj. odchudzenie go o informacje, których obecności program może się sam domyślić.
Zacznijmy od pierwszego.
Usunięcie buga dostępu
Trochę pomyślałem i stwierdziłem, że błędem było nie korzystanie z metody synchronized klasy Thread, ze względu na modyfikowanie obiektu z zewnątrz klasy przez inny wątek (np. zatrzymywanie generowania dźwięku z wątku Broadcaster). Doprowadziło to do paru zmian:
SoundWaveGenerator teraz rozszerza klasę Thread, zamiast jak wcześniej implementować klasę Runnable (aby móc korzystać z metody join).
Jeśli kogoś zastanawiało, kiedy tworzyć obiekty thread-safe, a kiedy odpuścić sobie synchronizację, odsyłam:
Do tego w Broadcaster.java już nie korzystam z:
while (!soundWaveGenerator.getAudioContext().isRunning()) {…czekaj 500 ms….}
tylko z:
soundWaveGenerator.join();
Czym różnią się obie metody?
Poza tym, że druga to wygodny one-liner, a pierwsza jest nieczytelna, bo polega na pętli sprawdzającej czy jakiś wątek nadal pracuje, a jeśli tak, to idzie na chwilę spać, to w zasadzie niczym (jeśli się mylę, to proszę o informacje).
Obie sprawiają, że wątek w którym zostały wywołane czeka, aż drugi wątek skończy pracę, a dopiero potem przechodzą do dalszego kodu. Było to potrzebne, bo kiedy chciałem wyłączyć generator dźwięku, to wyłaczenie nie działo się dokładnie w momencie, w którym o to poprosiłem. Musiałem więc poczekać, aż wątek na pewno skończy działanie, zanim znowu będę chciał skorzystać z dźwięku (co jak widać po błędach “Mixer already opened” nadal nie zawsze przed tym chroniło).
Do tego usunąłem:
audioContext.stop();
Które o ile było potrzebne wcześniej, bo zatrzymywało odgrywany dźwięk, to teraz zwyczajnie było źródłem błędów przy generowaniu dźwięku z bardzo krótkimi odstępami.
Sam nie wiem które dokładnie z powyższych naprawiło sprawę, ale teraz byłem w stanie przesłać pomyślnie literę w ciągu 750ms! W dodatku bez żadnego błędu dostępu, również przy przesyłaniu całych zdań i wyrazów.
W porównaniu do ostatniej wersji, gdzie “napis ćwiczebny” przesyłał się 26 sekund, czas przesyłania skrócił się do 12 sekund, w dodatku z mniejszą liczbą błędów transmisji.

Polecam sklonować z gita i sprawdzić samemu.
Suma kontrolna
Przejdźmy teraz do problemu weryfikacji przesłanych danych.
Skąd odbiorca może wiedzieć, czy nadawca wysłał pakiet informacji i np. po drodze przez zakłócenia nie dotarł kompletny lub przekłamany?
Na przykład, można przesłać takie informacje dwukrotnie, by porównać je po odebraniu. Ale przesyłanie informacji dwukrotnie to spore marnotrawienie czasu.
Co innego można więc zrobić?
Dołączać do wiadomości sumę kontrolną.
Suma kontrolna (ang. checksum) – liczba uzyskana w wyniku sumowania lub wykonania innych operacji matematycznych na przesyłanych danych, przesłana razem z danymi i służąca do sprawdzania poprawności przetwarzanych danych.
Wspomniane działania matematyczne mało nas interesują, sami lepszego algorytmu niż już stworzone nie wymyślimy, a sam fakt, że to po prostu nasz pakiet danych (w postaci zer i jedynek, bitów) po działaniach matematycznych, które mają na celu jak najmniejsze ryzyko kolizji powinien nam wystarczyć. Czym jest kolizja i jak długa ma być suma kontrolna?
Im większa suma kontrolna tym mniejsze prawdopodobieństwo kolizji, tj. sytuacji, kiedy ta sama suma kontrolna pasuje do więcej niż jednego układu bitów z których jest obliczana. Powiedzmy, że w trakcie przesyłu kilka zer zostanie odebranych jako jedynki i akurat dla takiego układu suma kontrolna przesłana przez nadawcę również będzie pasowała, wtedy odbiorca po obliczeniu swojej sumy kontrolnej i porównaniu z otrzymaną pomyśli, że dostał prawidłowy pakiet.
No dobrze, jak więc obliczyć tę sumę kontrolną? Szczegóły tego również nas nie obchodzą – Java udostępnia klasę która z podanej na wejściu tablicy bajtów utworzy 32 bitowej długości sumę kontrolną (algorytmem CRC, bo trzeba wiedzieć, że są też inne, nawet bardzo prymitywne sumy kontrolne jak bit parzystości).Tę sumę możemy dołączyć do naszej wiadomości.
 Wykonanie powyższego kodu wygeneruje na każdym komputerze ciąg 101110010001101101010101011110
Wykonanie powyższego kodu wygeneruje na każdym komputerze ciąg 101110010001101101010101011110
Tu pojawia się kolejny problem:
Dla przykładu, 32 jedynki i zera – 10001111110100001001111011100111 – to trochę sporo do przesłania dźwiękiem. Rozwiążemy to znowu zmieniając system liczbowy – tym razem na szesnastkowy. Podana wyżej liczba jest zapisana binarnie, natomiast zapisana hexadecymalnie będzie stanowić już tylko 8FD09EE7. Skrócenie 32 znaków do 8 to całkiem dobry wynik. W zasadzie, to skoro już dodajemy 6 liter alfabetu aby przesyłać szesnastkowo, to może dodać całą resztę liter i nie przesyłać ich żadnymi kodami ASCII? Dobry pomysł do wypróbowania, częstotliwości w naszym paśmie nadającym się do nadawania i odczytu powinno wystarczyć.
Checksum od właściwej części wiadomości będziemy oddzielać dodatkową częstotliwością nadawaną tak jak częstotliwość startu i końca wiadomości przez 3 * interwał pomiędzy znakami wiadomości, dla pewności, że odbiorca na pewno dostanie ten znak, bo inaczej źle zrozumie całą wiadomość.
Odchudzamy json
Jak już wspomniałem w poprzednim poście, struktura jsonu wygląda w ten sposób:

Dobre pytanie brzmi więc: jeśli oba komputery wiedzą jak wygląda przesyłany model i że pojawiają się w nich ciągi takie jak “jabłko” albo “miecz”, to czy opłacalne jest przesyłanie za każdym razem tych wyrazów? Nie lepiej dla nich zarezerwować jakiejś częstotliwości? (robi się trochę ciasno, jeśli mowa o wykorzystaniu kolejnych częstotliwości w naszym paśmie)
Oczywiście, że tak.
W jaki sposób to zrealizujemy?
Utworzymy tablicę z powiązanymi ze sobą nazwami zmiennych (np. “jabłko”) i odpowiadającymi im częstotliwościami. Następnie, po zamianie obiektu który ją zawiera na ciąg znaków (json), poszukamy w nim jakichś pod-ciągów które będą się pokrywać z tymi z tablicy, jeśli tak, to zamieniamy je na “$” + częstotliwość + “$”. Znak dolara jest po to, aby przesyłając ten ciąg do klasy Broadcaster, klasa wiedziała kiedy ma przesyłać znak jako znak ASCII a kiedy ma do czynienia ze zmienną i ma ją przesłać jako pojedyńczą częstotliwość.
Zrealizowałem to w ten sposób:

Powyżej jest klasa, z której będziemy generować jsona. Jak widać, dużo w niej nie ma, jeśli chcemy dorzucić jakiś klucz z wartością, to dodajemy go metodą putVariable.
Prawdziwa praca znajduje się niżej:
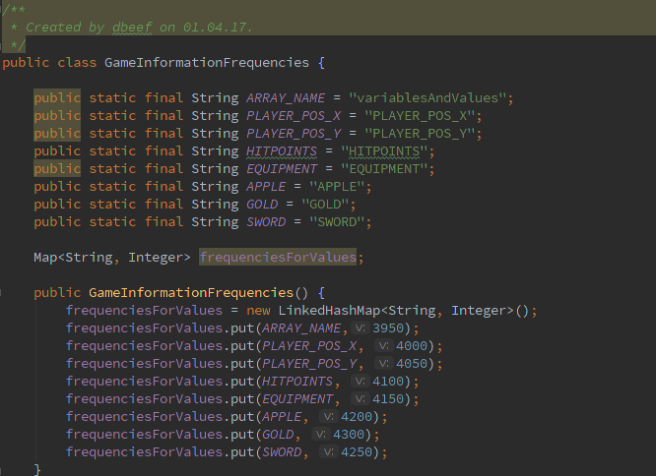
Tutaj deklaruję odpowiednie nazwy zmiennych wraz z odpowiadającymi im częstotliwościami.

Jeśli w metodzie translateJSONToSound natrafię na jakąś zmienną zadeklarowaną wcześniej w tablicy, to zamieniam ją na odpowiadającą jej częstotliwość.
Jak to działa w praktyce?
Oto kod, który wrzuca do obiektu z którego generujemy jsona miecz, jabłko, 50 złota i liczbę punktów życia. Do tego generuję z niego sumę kontrolną.

Wynikiem takiego programu jest:

Ale niekoniecznie musimy mieć akurat takie przedmioty w ekwipunku. Json jest bardzo elastyczny, mogę mieć np. tylko jabłko. Wtedy zwrócone zostanie:
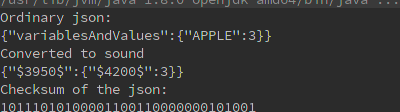
Litery składające się z 2-3 znaków decymalnych przesyłam 750-850ms, więc mając do przesłania 7 znaków (zakładam, że mam oddzielną częstotliwość dla ‘{‘, ‘:’,’}’ i cudzysłów włączam do wiadomości już po stronie odbiorcy, bo wiadomo, że nazwa zmiennej będzie objęta cudzysłowiem) plus do tego 8 znaków sumy kontrolnej, powyższy json powinienem przesłać w około 10 sekund. Spora różnica, w porównaniu do pierwszej wersji modemu, gdzie sam pojedyńczy znak przesyłałem ponad 4 sekundy.
Zostało dopisać interpretację kodów pomiędzy znakami dolara przez Broadcaster i Sniffer, ale nie jest to nic specjalnie skomplikowanego a ten post staje się już na to za długi. Zrobimy to przy okazji dorzucania modemu do gry.
W następnej części piszemy grę, zaczynając od pomysłu, wykonania prototypu, a dopiero na koniec połączymy to z modemem, aby można było grać w dwie osoby (chociaż w zasadzie, to gdyby się uprzeć, to tak jak w ramce sieci ethernet można dołączać nagłówek z informacją o tym kto nadaje pakiet i do kogo, grając w ten sposób w kilka osób, chociaż to mocno przedłużyłoby czas wysyłania).
Odnośniki:
Jak zawsze kod dostępny jest na GitHubie
https://github.com/dbeef/soundcoding

 Wygenerowane pliki.
Wygenerowane pliki.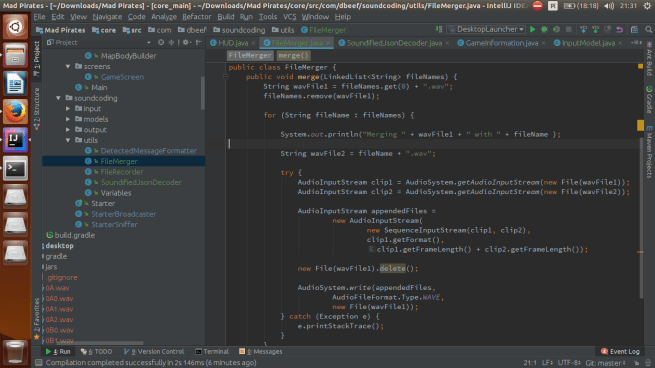 Klasa FileMerger.java którą łączę powstałe pliki .wav.
Klasa FileMerger.java którą łączę powstałe pliki .wav. Klasa FileRecorder.java która jest przerobionym tutorialem Beads ze strony:
Klasa FileRecorder.java która jest przerobionym tutorialem Beads ze strony:

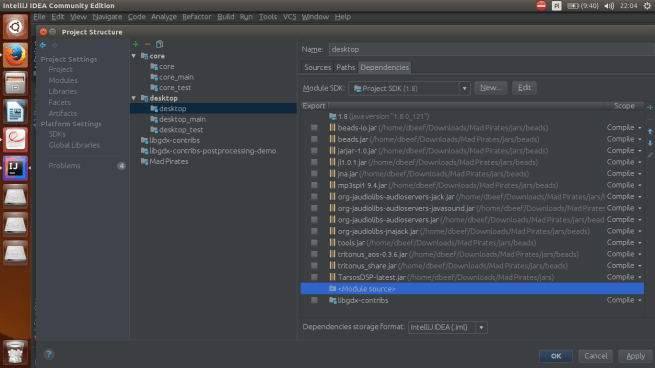 Prawidłowo podlinkowane libgdx-contribs
Prawidłowo podlinkowane libgdx-contribs Dot to klasa składająca się wyłącznie z wartości x, y oraz angle. Służy do zapisu kolejnych pozycji trajektorii do późniejszego rysowania.
Dot to klasa składająca się wyłącznie z wartości x, y oraz angle. Służy do zapisu kolejnych pozycji trajektorii do późniejszego rysowania. Rysowanie poszczególnych punktów przewidzianego toru ruchu. Rysuję tylko pierwsze 400 punktów.
Rysowanie poszczególnych punktów przewidzianego toru ruchu. Rysuję tylko pierwsze 400 punktów.
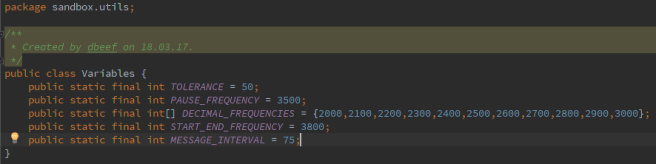 Zmieniona klasa Variables.
Zmieniona klasa Variables.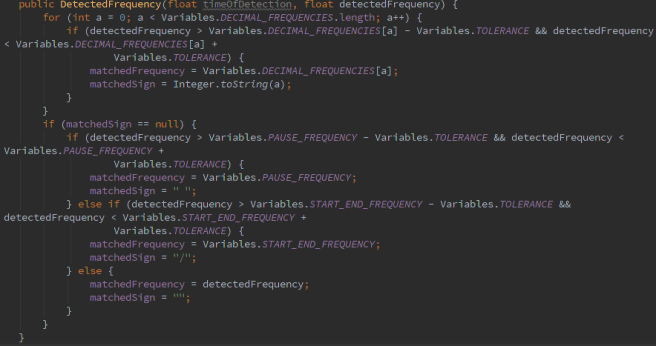


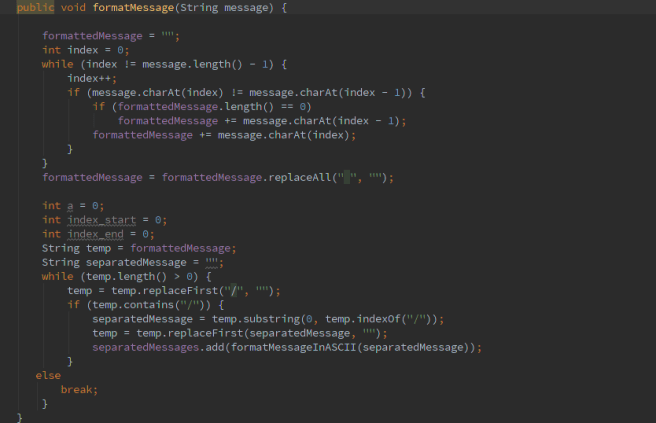
 Klasa Sniffer obsługjąca przechwytywanie dźwięku i interpretowanie go w tle.
Klasa Sniffer obsługjąca przechwytywanie dźwięku i interpretowanie go w tle.





You must be logged in to post a comment.