I started to make my writeup on 35C3-CTF’s task stringmaster1, but as I progressed I realized I’ll need another blog post to cover nuances of std::string without overstretching amount of input for a potential reader. Here we go, std::string byte-after-byte.
std::string in gdb
Imagine such a program:
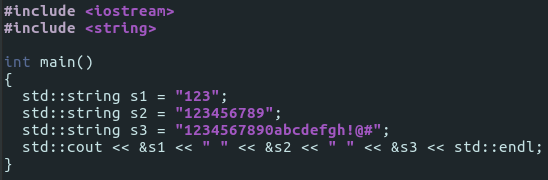
Being compiled in given manner:

Let’s start it in gdb and decompile main function:
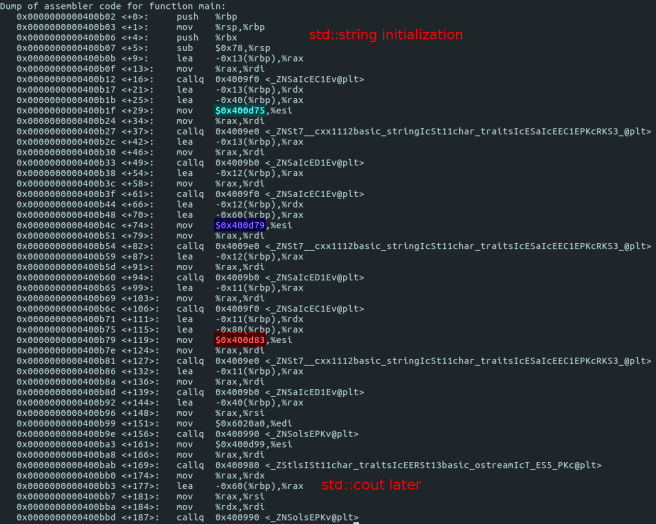
I highlighted 3 addresses: where do they point to?
As you probably know (and if you don’t, here’s a link to the Wikipedia):
The .data segment contains any global or static variables which have a pre-defined value and can be modified. That is any variables that are not defined within a function (and thus can be accessed from anywhere) or are defined in a function but are defined as static so they retain their address across subsequent calls.
Strings’ values that we hardcoded must be provided from somewhere, and addresses that disassembled code utilizes seems to point into .data segment. We can verify it by executing info variables in gdb, and scrolling to surroundings of this address:
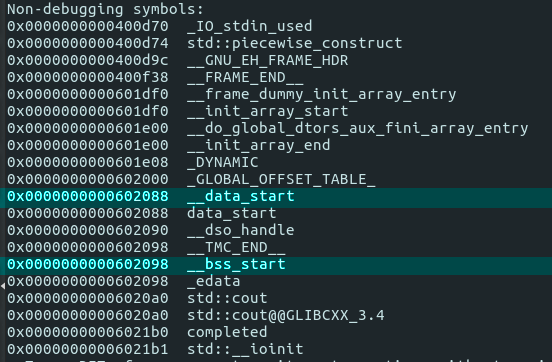
As you see, this address is above the __data_start symbol (it has lower address), so it must be declared in the .data section.
Figuring it out would be easier by calling nm string_example, out of gdb (gdb prints much more than we need).
But I am driving off topic, let’s focus on the strings themself.
Let’s breakpoint at some address at the end of the program, after we initialized all three of strings with given values and printed strings’ addresses:
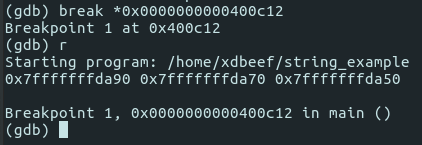
So strings’ addresses are:
s1 - 0x7fffffffda90 s2 - 0x7fffffffda70 s3 - 0x7fffffffda50
std::string takes 32 bytes on my x86_64 computer – one can verify that by running a program that prints sizeof std::string.
Since the strings are declared one after another, by printing 3 * 32 bytes after the address of first string, we’ll see all 3 of them:

x/24x 0x7fffffffda90 means: print next 24 [4 byte chunks] after 0x7fffffffda90 address.
You can simply calculate it by [bytes you want to be printed, [32*3] in our case / 4].
Here’s where the action starts.
Since we know that each std::string occupies 32 bytes, I’ll colorize them by different colors and label by variable name:

We know lengths of our strings, which are:
s1 - "123" - 3 - 0x3 s2 - "123456789" - 9 - 0x9 s3 - "1234567890abcdefgh!@#" - 21 - 0x15
Can we identify such bytes on the image? Yes. That’s the 4’th column on the image above:

From looking at the sources (we’ll cover them later) I know, that length should be 64 bit value, so length takes 2 columns (2 x 4 bytes = 64 bits).
What else can be identified?
Individual characters we put into the strings.
Look at the first and second column – 0x34333231 and then 0x38373635, and then 0x39, when converted from ascii values present what that string contain:

Marking our finding on the image with ‘d’ character, as an abbreviation from ‘data’:

But wait, look at the s3, the longest one – where’s the data we supplied? It doesn’t appear in the same manner as on the other strings… We’ll come to this in a second.
In the meantime – look at the first 4 bytes of our strings, on the second column.
In s2 and s1 it appears, that this value points (stores an address of) to the ‘d’ section.
So this value must be the pointer to the string’s data!
Again, mark our finding to the image with ‘p’, as from ‘pointer’:

And that answers the question stated just before – s3‘s data is stored away from the actual string, under 0x00614c20. Printing it reveals the string that we put into s3 before:

Which make:

That makes a question: why are some strings stored locally, and some externally, on the heap?*
And a question that watchful reader would state – what’s stored on the column we didn’t mark, between 4th and 8th bytes of std::string?
*We know, that address 0x00614c20 is on the heap, since we can check heap start/end addresses via info proc mappings in gdb:
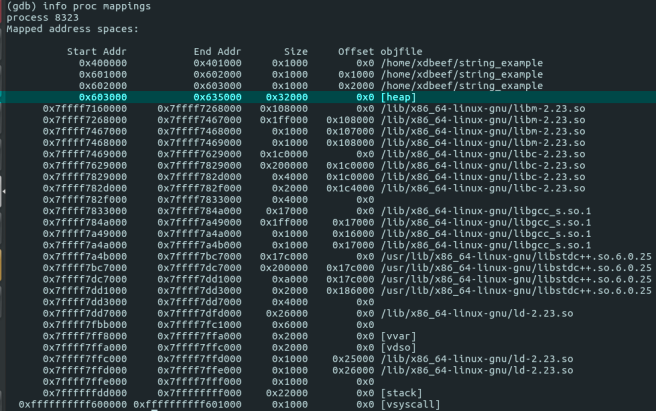
0x00614c20 is bigger than 0x603000, but smaller than 0x635000.
std::string in sources
Answer to those questions lies in std::string’s sources.
You can access them, i.e by opening them in your IDE, like CLion – press Ctrl + N and type string – it will look for class definition.
Other way is just printing it from the command line, like:
pygmentize /usr/include/c++/8/bits/basic_string.h
One way or another, we’ll find std::string definition. The chunk which interested me is:
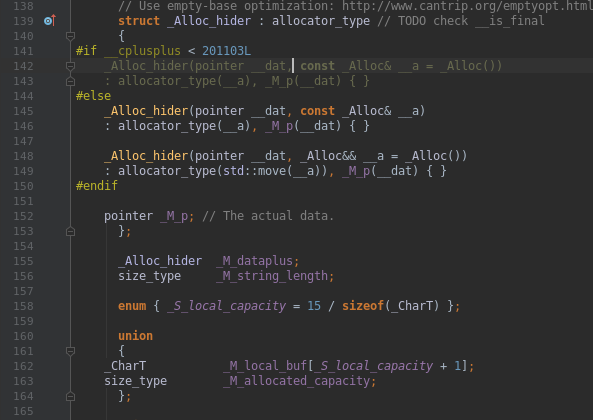
It defines string’s fields that we’ve marked on images. There’s string’s length, pointer to its data, an array for local data (defined as a union of either capacity or array of 15 bytes) – and the field we couldn’t figure out – allocator_type. Let’s mark it on the image:
That makes sense! The s1 and s2 strings we declared, which both had their data stored locally, have the same bytes in the data_allocator field, and data_allocator of s3 is zeroed.

So there’s a different string allocator used, depending on string’s length. Local buffer’s size is 15 bytes, so if we try to allocate a bigger string, like in case of s3, it’s going to allocate on heap instead. This optimization has its name and is called:
small string optimization
If you want to read more about it, here are the sources I used:
https://blogs.msmvps.com/gdicanio/2016/11/17/the-small-string-optimization/
There’s more – std::string::npos
As the cpprerefence states:
This is a special value equal to the maximum value representable by the type
size_type. The exact meaning depends on context, but it is generally used either as end of string indicator by the functions that expect a string index or as the error indicator by the functions that return a string index.Note
Although the definition uses –1, size_type is an unsigned integer type, and the value of
nposis the largest positive value it can hold, due to signed-to-unsigned implicit conversion. This is a portable way to specify the largest value of any unsigned type.
On my x86_64 platform, given program:

prints:

it’s 16 times F, since:
byte = 8 bit, max value is 0b11111111 = 2 ^ 7 + 2^6 + … + 2^0 = 128 + 64 + … + 1 = 255
byte in hex = 0xff, max value is (F * 16 + F) = 15 * 16 + 15= 255.
so in other words – it’s 8 bytes = 64 bits.
But I’m mentioning it since there can be programs that use it without sanitization, like:
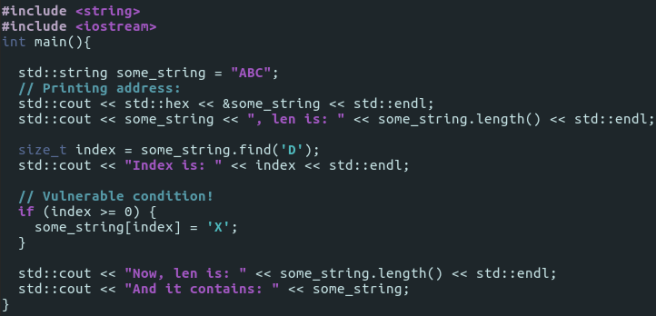
Which prints:
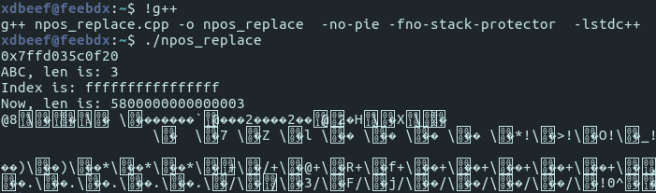
As the condition we provided lacked checking if index is equal to npos, we’ve overwritten the length of some_string, and consequently made it to try printing all
0x5800000000000003 bytes that proceed address pointed by some_string‘s data pointer.
Let’s make 2 another strings in this program, and check if same thing happen to their lengths:
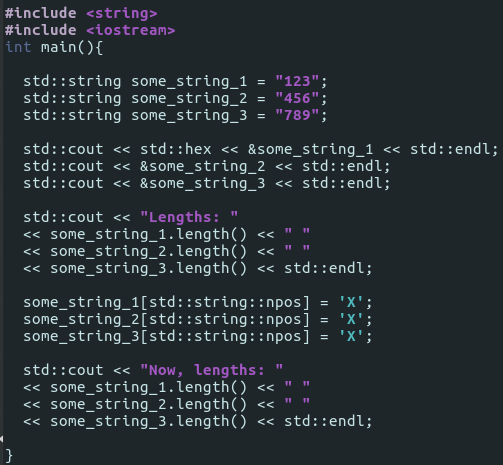
That prints:

So it’s repeatable! But why? How come, that
some_arbitrary_string[std::string::npos]
points to its length, always?
Well, as you probably know – variables can be overflown, and pointers also.
I’ll give you a short example of unsigned char overflow and then, pointer overflow – since they work in the same way:
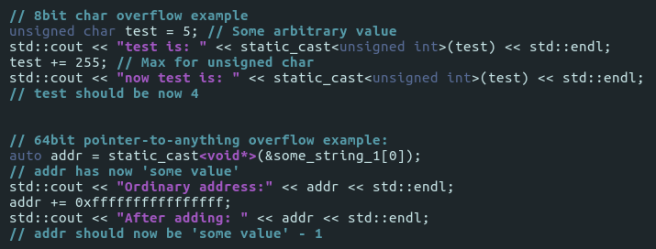
It prints:
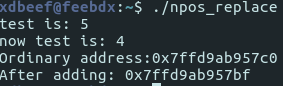
If we’re adding some value, to the value that’s already a maximum value for this platform, we’ll end up with… ‘some value’ minus 1!
As you learned before in this post, std::string’s length is 8 bytes before its local data. So if we’ll overflow pointer to the local data by adding max value it can hold, we’ll end up 1 byte before its local data, in length’s area, and that’s why some_string[std::string::npos] will always point to its length(…’s last byte)!
Conclusion
I wish I could just find blog post like this on the internet instead of writing it myself.
