Lista problemów które udało mi się rozwiązać od ostatniego postu:
Wyświetlanie mapy większej niż 256×256
Znalezienie jakiegoś programu do edycji map kafelkowych, kompatybilnego z gba/nds
Zrobienie prostego generatora poziomów
Sprawdzanie kolizji poszczególnych kafelków z punktem x,y wyznaczonym przez dotyk na ekranie
Znalezienie w gimpie opcji konwersji kolorów do takich, które spodobają się libnds (8 bit, indeksowane bmp/png)
Wyświetlanie mapy większej niż 256×256
Przypominając, wyświetlenie mapy kafelkowej w libnds składało się do skopiowania z pamięci tablicy (w przypadku 256 px na 256 px daje to mapę wielkości 1024, bo każdy element mapy zajmuje 8×8 pikseli) do odpowiedniego rejestru w hardwarze NDS.
…można się dowiedzieć, że rysując mapy większe niż 256×256, trzeba rozpatrzyć specjalny przypadek – weźmy na przykład mapę 512×512 z jakiej teraz korzystam w spelunky-ds.
Dzielę moją tablicę 4096 elementów na 4 sektory, jak szachownicę. Robię to tworząc zapasową tablicę, a następnie przechodzę przez nią tak, aby dojść tylko do odpowiedniej połowy na każdej z osi (wiersz ma szerokość 64 elementów, więc dochodzę do 32). Reszta chyba jest oczywista:
Da się to skrócić, ale to dobry przykład bo widać każdą oddzielną pętlę for odpowiadającą za oddzielną część szachownicy.
Nie wiem czy to część całego standardu C++, ale zauważyłem, że jeśli nie przydzielę pamięci dla tymczasowej tablicy poprzez malloc, to całość nic nie wyświetla (żadnych błędów, po prostu jakby DMA stwierdzało że nie skopiuje tej tablicy już w runtimie), więc trzeba na to zwrócić uwagę.
Znalezienie jakiegoś programu do edycji map, który generowałby tablicę C++
Strona wygląda jakby ledwo się trzymała, więc chyba na wszelki wypadek wrzucę binarkę na moje repozytorium z dopiskiem do readme o odpowiedniej licencji i autorze.
Mappy potrzebuje tilemapy – robię ją w gimpie sklejając odpowiednie pliki i koniecznie konwertując je do .bmp, indeksowanego, 256 kolorów (8bit).
Ten sam plik, ale w formacie .png przekazuję do folderu gfx w folderze od spelunky-ds.
To co wychodzi z mappy, to tablica, którą można wkleić bezpośrednio w kod:
Najmniejsza jednostka podziału grafiki w libnds to kafelek 8×8 (chociaż pewnie można zmienić to w programie grit), ale moje grafiki ze Spelunky są rozmiarów 16×16, więc aby 4 kafelki trzymały jedną logiczną część (np. dla momentów w którym niszczę cały kafelek) stworzyłem klasę MapTile:
values zawiera 4 wartości dla 4 różnych kafelków 8×8, map_index zawiera ich adresy w mapie.
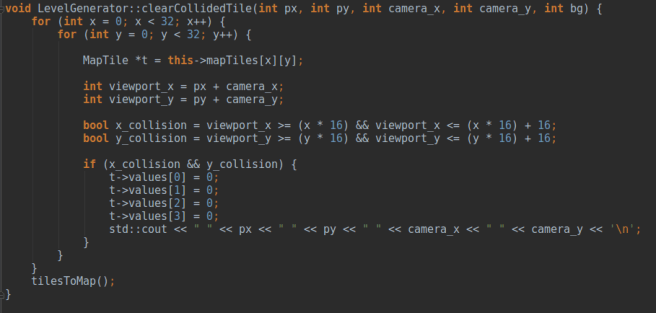
Sposób wybierania adresów w mapie jest dość żmudny i nie ma co go tutaj przedstawiać, kto jest zainteresowany niech zobaczy plik LevelGenerator.cpp, w szczególności funkcje:
generateRooms()
mapFrame()
Mamy już pozycję każdego kafelka, można więc mając pozycje dotknięcia na ekranie sprawdzić teraz, czy któryś z nich nachodzi na ten x,y.
Trzeba pamiętać jednak o szczególe, takim jak pozycja kamery. Sprawdzając kolizję, trzeba sprawdzać pozycję x i y kafelka PLUS pozycja x i y kamery, tak jak poniżej:
Po pobraniu wrzucam go podpisanego jako cavebg.bmp do folderu gfx/tilemaps. W nim napisałem następującą regułę grit (wytłumaczenie – odsyłam do docsów grit):
-p!
-gt
-gB8
-mRtpf
-mLs
-mu32
-Mw16
-Mh16
Mój Makefile (gdzie wskazuję gritowi jakie foldery ma odwiedzić) możecie sprawdzić na Githubie spelunky-ds.
2
Teraz kopiujemy odpowiednie pliki z przykładowego projektu do naszego projektu:
scrolling.cpp
TextBackgrounds.s
Do main.cpp wystarczy skopiować jedynie linie (podmieniłem argument tak aby pasował do naszego obrazka cavebg):
Robimy mapę. Ściągamy edytor który podlinkowałem wyżej.
Tworzymy nową mapę przez File->New map. Korzystamy z faktu, że pojedyńczy tile w NDS jest rozmiarów 8×8, nasz obrazek to 32×32 a rozmiar mapy jaki wybraliśmy to 256×256 – będzie więc miała szerokość i wysokość 32, szerokość i wysokość tile-a 8×8 co podajemy w oknie które wyskoczy.
Importujemy obrazek .bmp który stworzyliśmy wcześniej opcją File->Import.
Rysujemy cokolwiek i eksportujemy do pliku txt przez File->Export as text, w oknie które się pojawi niczego nie zmieniamy.
W pliku txt który się wygenerował interesuje nas pierwsza tablica od góry.
Ponieważ nie do końca wiem, czy to jakaś rzecz wynikająca z C++ czy mój błąd, na razie nie kopiuję tej tablicy bezpośrednio do kodu, ale podmieniam wartości w pliku TextBackgrounds.s – inaczej nie działa.
Miejsce które trzeba podmienić, to Layer256x256Map (ponieważ taki rozmiar mapy wybraliśmy). Miejsce to deklaruje wygląd mapy.
Wyrzucamy wszystko co jest po Layer256x256Map i jest przed:
@}}BLOCK(Layer256x256)
Teraz ważna rzecz – nie wklejamy tu bezpośrednio tej tablicy. Przepuszczamy ją przez prosty program który napisałem (zmienia tablicę 2d na 1d, zmienia wartości z decymalnych na hexy + dodaje “.hword” na początku każdej linii) wklejamy dopiero output, który wypuścił ten program.
Wrzuciłem jego source do Githuba projektu, do folderu utils. Przed uruchomieniem trzeba wkleić swoją własną mapę do jego kodu.
Wynik
Mamy scrollowalną mapę jak poniżej:
Co dalej
Zastanawiałem się więc w którą stronę pójść – wyświetlać jako tiled background jedynie te faktycznie statyczne elementy (tło które jest za niszczalnymi elementami), wyszczególnione tutaj:
…a zniszczalne elementy wyswietalać jako sprajty. Wtedy logika wyświetlania zniszczonych elementów byłaby prostsza, zero kombinowania, tak samo sprawdzanie kolizji, np. z kolcami czy podmiana sprajta, jeśli np. ten element wybuchł. Plus wszystkie wartości pomocnicze trzymane byłyby w jednej strukturze.
Pytanie tylko, czy wyświetlanie tego w ten sposób jest dobre – NintendoDS ma rzekomo oddzielny układ odpowiedzialny za wyświetlanie backgroundów, nie obciążałbym więc CPU, po prostu kopiowałbym pamięć do odpowiedniego rejestru przez Direct Memory Access, gdybym nie używał sprajtów tylko wyłącznie background. Być może NDS ma też oddzielny układ do wyświetlania sprajtów i nie musiałbym zastanawiać się jak będzie to wyglądać wydajnościowo – problem w tym:
On the Nintendo DS, we can have up to 128 sprites.
Więc raczej by to nie wyszło, mapa w Spelunky to około 40×40, nie mówiąc o postaciach czy przeszkodach.
Size was one of the benefits of using tilemaps, speed was another. The rendering of tilemaps in done in hardware and if you’ve ever played PC games in hardware and software modes, you’ll know that hardware is good. Another nice point is that scrolling is done in hardware too. Instead of redrawing the whole scene, you just have to enter some coordinates in the right registers.
Drugi pomysł, wykorzystujący w 100% tylko backgroundy, to napisanie pomocnicznego programu, który przejdzie przez plik txt z generatora map i stworzy tablicę elementów (powiedzmy, że nazwiemy te elementy SpriteElement {x, y, typ elementu (zwykły klocek, klocek tła, itd), boolan czyZniszczony, szerokość, wysokość, wskaźnik na tablicę intów który będzie wskaźnikiem na hexy ekwiwalentu tego samego tile-a, ale zniszczonego}).
Wtedy za każdą zmianą takiego kawałka tła (np. zniszczeniem pojedyńczego klocka) będzie można robić wpis do rejestru ze zmienioną tablicą i tło nadal będzie się jakoś wyglądać – to które to będą element listy i na jaką wartość ją podmienić będzie wiadomo ze SpriteElement. Kolizje i odpowiednia logika również wyszłaby z tego.
Plus, i tak muszę zrobić coś co będzie w stanie wygenerować mapę od zera (w Spelunky każda mapa jest losowa, generowana proceduralnie) więc jakieś makra pod poszczególne kafelki będę musiał gdzieś w kodzie zadeklarować.
Wkrótce napiszę jakąś wstępną implementację.
Efekt powyższego tutoriala można zobaczyć na Githubie tego projektu:
PS: Zauważyłem, że kolejne hexy: 0x0001, 0x0002, 0x0003…0x000F to kolejne elementy (8×8 tile) naszego obrazka .bmp. Składa się to w całość – gdyby ułożyć je warstwami po 4, narysowalibyśmy nasz obrazek. Można w ramach eksperymentu wkleić coś takiego do pliku TextBackgrounds.s:
Wziąłem się za ustawienie środkowiska pod libnds (nie będę w końcu pisał całej gry w vimie). Pobrałem CLiona, żeby mieć ze sobą wszystkie najlepsze udogodnienia z Intellij którego używam na codzień do Javy – problem w tym, że CLion nie ma wersji community, jedynie 30 dniowy trial. Trzeba będzie pojanuszować i ściągać ponownie za miesiąc (jakoś nie mam ochoty na wydawanie 200€ na rok).
Wrzuciłem też gotowy projekt na githuba, teraz można śledzić progress:
Na start gry, zdanie po zdaniu, z interwałem ~2.5s, odkrywane są kolejne linie intra. Chcemy napisać klasę, która będzie odpowiedzialna za takie przerywniki.
Za szablon wziąłem sobie plik z przykładów devkitPro/examples/nds/Graphics/Printing/customFont.
To jest miejsce w którym zapoznam się z timerami w libnds. Każda z linii pojawia się co określony odstęp czasu, który trzeba sobie odliczyć. Z tego co znalazłem w docsach i wypróbowałem, za odliczanie czasu odpowiada specjalny układ na płytce DSa, a właściwie jeden z czterech układów, w zależności który wybierzemy.
Start i zatrzymanie układu wygląda następująco:
Wygląda to tak:
w pierwszym argumencie podajemy który timer używać
w drugim podajemy jakiego dzielnika używać, czytaj – co jaki czas ma być naliczany ‘tick’ timera
trzeci – liczba ticków która musi minąć, zanim bufor timera się przepełni
funkcja która ma być wywołana w momencie, kiedy bufor się przepełni
Przykładowo, napisałem taki kod, który ma za zadanie co około sekundę wypisać na konsolę NDS czas jaki upłynął (wytłumaczenie w komentarzach):
Efekt wygląda tak:
Wracając więc do tego co mamy zrobić, to inicjalizujemy zmienne int trzymające wartości czasu w milisekundach i zdejmujemy z nich upłynięty czas. Jeśli upłynął i nie ustawiliśmy jeszcze flagi ‘narysowano’, to wywołujemy funkcję wypisującą na konsolę i ustawiamy flagę na 1. Robimy tak dla każdej z trzech linii.
Timery dla każdej z linii ustawiłem jako tablicę:
{1000, 3500, 6000}
Z czego można się domyślić, że pierwsza linia wyskoczy po sekundzie, druga po 3.5, trzecia po 6.
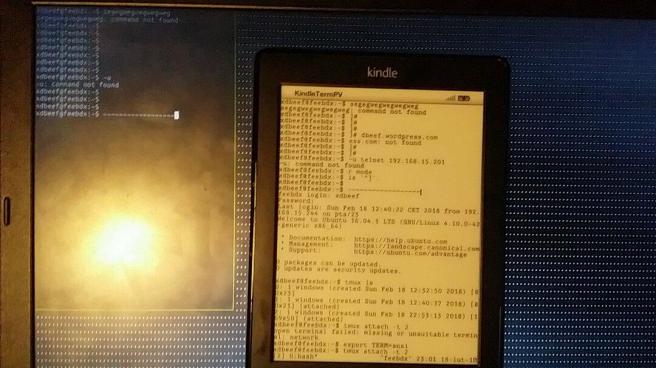
Przyszło mi do głowy, aby zrobić użytek z rozbitego Kindla którego już nie używam. Myślałem na początku o stacji pogodowej (Kindle obsługuje javę, więc może nawet mógłbym napisać coś własnego po wrzuceniu jailbreak-a), ale wtedy zobaczyłem to:
Okazuje się, że sporo osób włożyło wysiłek w to, aby móc używać Kindle jako ekranu terminala (mógłby mi się przydać, jako dodatkowy ekran na listę rzeczy do zrobienia, do wrzucenia htop-a i monitorowania zasobów albo irca).
Udało mi się, efekt wrzucam tutaj, a poniżej zagregowałem wszystkie materiały, które są potrzebne aby krok po kroku przeprowadzić to samo na innym Kindlu 4 (non-touch), razem z własnymi uwagami i zdjęciami (efekt spodobał mi się na tyle, że zrobiłem to samo także na drugim, sprawnym Kindlu, więc była okazja na spisanie/zrobienie zdjęć ze wszystkiego).
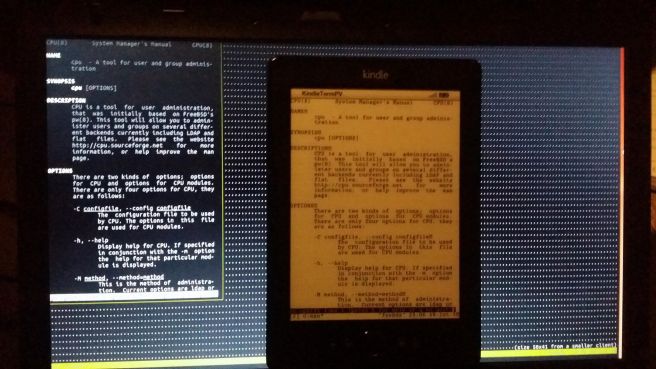
Przykładowy manual wyświetlony na Kindlu:
Htop z mojego laptopa, wyświetlany na kindlu:
Midnight commander
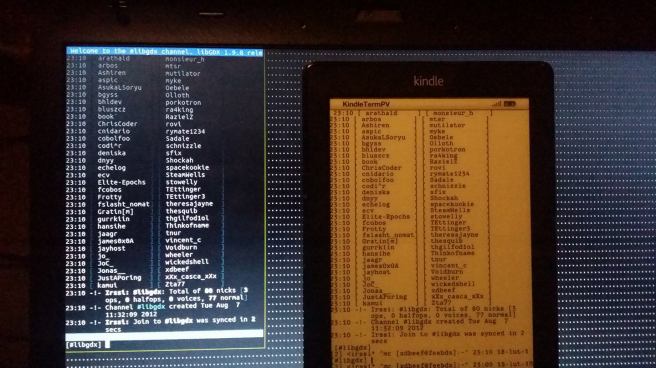
Irc
Instrukcje
Nie ponoszę odpowiedzialności za zepsute Kindle!!!
Max czas jaki zajmie wszystkiego poniżej to 60 minut.
1
Pierwszym co trzeba zrobić, to zainstalować jailbreak stworzony przez społeczność.
Wersja pod Kindle 4 NT wraz z instrukcjami i odpowiednim plikiem jest tutaj:
Ważna rzecz – spiszcie sobie gdzieś lub zróbcie zdjęcie numeru seryjnego waszego Kindla – będzie potrzebny w punkcie 4.
Numer seryjny będzie wyświetlony w menu diagnostycznym które pojawi się, kiedy będziecie przechodzić przez instrukcje od jailbreaka, będzie wygladać tak jak na zdjęciu poniżej:
Inna rzecz którą wydaje mi się, że nie można pominąć, to sprawdzić wersję softu – u mnie na obu Kindlach było to 4.1.3, a podlinkowany jailbreak powinien działać od 4.0.0 do 4.1.3. Wersję softu można sprawdzić w ustawieniach, będzie wypisana na dolnym pasku.
Poza tym, wydaje mi się, że nie ma tu zbyt wiele do tłumaczenia.
Paranoicy mogą też podładować baterię do 100% przed całą operacją.
Po skopiowaniu wskazanych w tutorialu plików na wierzch pamięci Kindla i przejściu przez resztę kroków, podczas uruchamiania pojawi się taki ekran:
2
Drugi krok, to instalacja usbnetwork – pozwoli to po podłączeniu Kindla kablem USB udawać komunikację przez ethernet (mniam), zainstaluje serwer ssh na Kindlu plus zdejmie ekran “USB Drive Mode”, kiedy Kindle jest podłączony do komputera (przyda się później).
Instrukcje z README_FIRST.txt z pobranego pliku powinny być jasne, ale je powtórzę:
Kopiujemy plik Update_usbnetwork_0.57.N_k4_uninstall.bin na wierzch pamięci Kindla (tak jak w przypadku jailbreaka)
Uruchamiamy instalację poprzez:
[Menu] -> Settings -> [Menu] -> Update Your Kindle.
Stosowne zdjęcie wymienionego ekranu:
3
Po restarcie poprzedzonym instalacją usbnetwork jesteśmy gotowi, żeby połączyć się z Kindlem przez ssh.
Noooo prawie. To co trzeba zrobić po każdym restarcie, aby uaktywnić usbNetwork, to:
Wcisnąć przycisk klawiatury, wpisać ;debugOn (razem ze średnikiem), wcisnąć klawiaturowe “Done”, a następnie search my items” z paska. Po wszystkim nie będzie żadnej widocznej reakcji, Kindle po prostu odświeży ekran.
Po tym, zrobić to samo, ale wpisać ~usbNetwork (razem z tyldą)
Teraz można podłączyć Kindle przez kabel usb.
Po podłączeniu Kindla, można ustawić sobie adres poprzez ifconfig, ale z tego co zauważyłem, połączenie lubi się zrywać po kilkudziesięciu sekundach, jeśli połączenie nie będzie dodane do Network Managera.
Z readme dowiadujemy się, że Kindle 4 będzie przyjmował połączenia tylko z adresu 192.168.15.201, więc po podłączeniu go edytujemy powstałe połączenie (Ubuntu -> “Network connections”) i ustawiamy taki przez interfejs gnome do Network Managera.
Statyczny adres, pod jakim Kindle będzie w sieci, to 192.168.15.244.
Tutaj przyda się numer seryjny który spisaliśmy wcześniej. Po nim dowiemy się, jakie są możliwe hasła roota do Kindla. Wpisujemy go pod poniższym adresem:
Polecam jednak rozegrać to trochę inaczej – w końcu mamy teraz dostęp przez ssh.
Rozpakowujemy na komputerze pobrany keystore (na tę chwilę jest to 2012-11-06) i odpalamy Midnight Commander.
W otwartej wcześniej sesji ssh, wpisujemy mntroot rw, a w oknie Midnight Commandera. Wybieramy w lewym górnym rogu [Left] -> [Shell link] -> [root@192.168.15.244].
Po zalogowaniu się, przechodzimy do /var/local/java/keystore/.
Jest możliwość, że zastaniemy tam już istniejący plik o takiej samej nazwie, wtedy zatrzymujemy go w razie czego pod inną nazwą, np. poprzez [F6] i wpisanie *_old i kopiujemy nasz developer.keystore.
Po całości trzeba zrestartować Kindle (keystore ładowany jest tylko raz, na start), co za tym idzie od nowa wpisywać ;debugOn i ~usbNetwork – jeśli chcecie sobie tego zaoszczędzić, to przejdźcie od razu do następnego punktu, bo po nim również przyda się restart.
zrobił super robotę, zmienił i skompilował javowy emulator z Kindle w wersji dotykowej/w wersji z klawiaturą na wersję która uruchomi się na Kindle 4 który nie ma żadnego z wymienionych.
Powstaje pytanie – jak w takim razie wpisać jakąkolwiek komendę na takim Kindlu? To za chwilę.
I kopiujemy ją (kindleterm.azw2) do katalogu ‘documents‘ który jest na wierzchu pamięci Kindla (jeśli chcemy to zrobić przez mc, to miejsce to jest zamontowane w /mnt/us).
Po tym modyfikujemy plik /opt/amazon/ebook/security/external.policy w taki sposób, aby po “grant signedBy “Kindlet” {” zawierał linie:
a na komputerze tworzymy plik o nazwie remote_keyboard.properties z taką zawartością:
host 192.168.15.244
port 3333
Wtedy umieszczamy w tym samym miejscu co powyższy plik wrzucony wcześniej na Kindla KindleTERM i odpalamy:
java -cp kindletermpv.azw2 kindle.RemoteKeyboard
Powinno pojawić się okno swingowej aplikacji – klikamy w jego środek i piszemy cokolwiek – dokładnie to samo powinno pokazać się na ekranie Kindla!
Jak pozbyć się tej aplikacji i pisać bezpośrednio w terminalu z komputera? Z pomocą przychodzi tmux i serwer telnet. Wszystko idzie po kablu usb, więc wątpię żeby użycie telnetu było jakimś zabezpieczeniowym faux-pas, chyba że ktoś zdecyduje się łączyć z Kindlem po wifi (nie próbowałem).
Jeśli jeszcze nie mamy, to instalujemy serwer telnet i aplikację tmux.
Gdy już mamy to:
Na komputerze wpisujemy ‘tmux’
Na Kindlu wpisujemy ‘telnet 192.168.15.201’ i logujemy się na swoje konto z komputera.
Na Kindlu wpisujemy export TERM=ansi (bez tego nie zadziała tmux ani praktycznie nic innego)
Na Kindlu wpisujemy ‘tmux ls’, zapamiętujemy numer sesji która ma najnowszą datę utworzenia
Na Kindlu wpisujemy ‘tmux attach -t [numer sesji, np. 2]
Gotowe !!!
Teraz cokolwiek będzie wpisanego na komputerze, pojawi się na oknie na Kindlu (można wyłączyć już javową apkę).
Koniec.
Duże podziękowania dla wszystkich osób które udostępniły potrzebne materiały na blogach/forach.
Wpis na blogu w którym opisane jest jak zautomatyzować proces łączenia tak, żeby używać Kindla w charakterze ekranu dla Raspberry:
John the ripper, myślałem na początku o wydobyciu hasła do roota z zakodowanego /etc/shadow (defaultowo można zalogować się na użytkownika o standardowych uprawnieniach bez generatora haseł, u:framework p:mario, wtedy można wydobyć ten plik).
Zastanawiało mnie trochę zrobienie tego na kilku urządzeniach jednocześnie (jeśli byłoby konieczne iteracyjne odgadywanie haseł), bo okazuje się że JTR używa tylko jednego rdzenia – odgadnięcie hasła zajęłoby tygodnie działania.
Obeszło się bez użycia JTR, ale to jest to co znalazłem przy okazji:
W tej serii na warsztat chcę wziąć istniejącą grę Spelunky i przepisać ją na konsolę Nintendo DS.
W pierwszym poście chcę jedynie pokazać możliwości a nie wprowadzić od podstaw do libnds – to być może przedstawię w innych postach (pisanie na dsa wydaje mi się dobrym wprowadzeniem do programowania na systemach embedded), tymczasem poniższe jest ciekawostką.
Przedstawienie Spelunky
Spelunky to darmowa gra napisana przez Dereka Yu w 2009 (która dorobiła się kontynuacji w 2012) z gatunku cave-exploration.
Spelunky is a cave exploration / treasure-hunting game inspired by classic platform games and roguelikes, where the goal is to grab as much treasure from the cave as possible. Every time you play the cave’s layout will be different. Use your wits, your reflexes, and the items available to you to survive and go ever deeper! Perhaps at the end you may find what you’re looking for…
Wydanie Spelunky przypadło na moje lekcje informatyki w gimnazjum (R.I.P), nie miało konkurencji przez to że waży tylko 9.5 MB, nie wymaga instalacji i działa bez problemu przez Wine.
…więc jest to świetny cel do przeniesienia na inną platformę (pomijając fakt że Spelunky zrobione są w Game Makerze i wydobycie czegoś z udostępnionych plików .gmk wymaga posiadania wymienionego).
Gameplay z komentarzem:
Wydobycie grafik
Znalezienie assetów oryginalnych Spelunków zacząłem nie od Game Makera ale od Githuba (z przeczucia że ktoś już próbował ruszyć temat).
Właśnie to ostatnie było tym czego szukałem, skatagolowane pliki gry z odpowiednimi podpisami i kodem. Miałem już wszystko co potrzebne.
Przedstawienie libnds
Libnds wraz z przykładami dostarczany jest wraz z projektemdevkitProktóry zbiera wszystkie narzędzia potrzebne do pisania amatorskich programów na ds-a.
Do zautomatyzowanej instalacji devkitPro na linuksie udostępniony jest skrypt który wystarczy uruchomić interpreterem perla:
Po całej operacji brakuje tylko jednej rzeczy – emulatora NintendoDS – tutaj zdaje się że najlepszą opcją jest desmume.
Po przejściu do ~/devkitPro/examples/nds/Graphics i pierwszym uruchomieniu narzędzia make poproszeni zostaniemy o dodanie zmiennych DEVKITPRO i DEVKITARM do /etc/environment.
Po drugim uruchomieniu zbudowane zostaną pliki .nds, które będzie można włączyć emulatorem. Np. ~/devkitPro/examples/nds/Graphics/3D/3D_Both_Screens:
Zamierzam zrobić jakiś mały tutorial pisania na ds-a w następnych postach, więc daruję sobie przedstawianie szczegółów teraz. Gdyby ktoś szukał materiałów do nauki, to w kolejności od moim zdaniem najlepszych:
Użycie oryginalnej czcionki Spelunky do programu na ds-a
Najprostsze wprowadzenie jakie może być, bo polegające na wypisaniu tekstu w konsoli-konsoli. Jedyna różnica, to użycie czcionki innej niż systemowa.
Na bazie przykładu z ~/devkitPro/examples/nds/Graphics/printing/custom_font widać, że potrzebny będzie tilesheet z złączonymi wszystkimi znakami jakie potrzebujemy, aby móc pisać własną czcionką na ekranie ds-a.
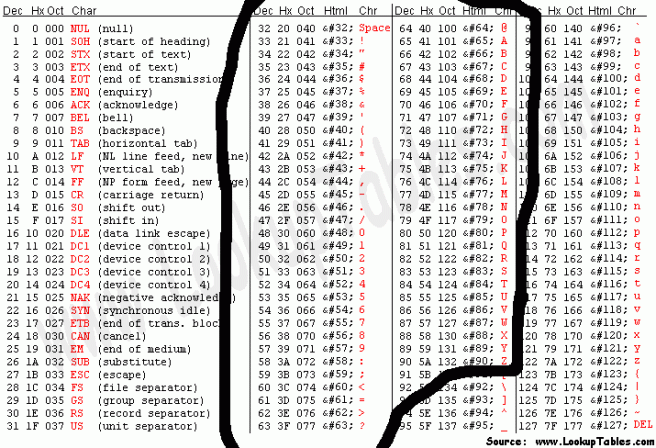
W pobranym SpelunkyCommunityUpdateProject /spelunky/Sprites/sFont.images dostępne jest 59 znaków (od spacji do ‘Z’) w oddzielnych plikach ponumerowanych od 0 do 58, co odpowiada kodom znaków z tabeli ASCII przesuniętym o 32 (istotne później):
Do złączenia tych znaków w jeden plik wykorzystałem narzędzie online Stitches:
Aby Stitches nie zmieniło kolejności i wygenerowało jedną kolumnę ze znakami dokładnie w tej kolejności jak w tabeli ASCII, musiałem zmienić nazwy plików ze znakami tak jak poniżej (inaczej mocno się przetasowywało), czyli co 10 plików dodając kolejną literę alfabetu:
Po całej operacji Stitches wygenerowało taki plik:
Teraz ważna rzecz:
używane grafiki, muszą przejść przez (dołączony w devkitPro) program grit, wtedy w kodzie dołączone są jako plik nagłówkowy (z obrazek.bmp powstaje obrazek.h dołączony jako #include <obrazek.h>). Wytłumaczenie z tutoriala patater:
Working with the Makefile
The default template makefile will turn your graphic files into object files for linking into your program. Never include data as a header file.
The graphics must be in a lossless image format, such as gif, tif, bmp, or png in order to work with the provided template makefile. I prefer the png graphic format. Image conversion is usually done by a program called grit. The provided template makefile will ask grit to convert images in the gfx folder of your project root to a format ready for the Nintendo DS.
The provided template makefile, adapted from the default libnds template makefile, is a good base for most all projects. It will look in a folder called gfx (in the same directory as the makefile) for your graphics. If any are found, it uses a special bin2o rule to tell grit to turn your images into .o files, according to grit rule files (with the .grit files extension), which can be linked into your program. grit will create a header file (.h) for your data. The name format for them works like so: if a file is called orangeShuttle.png the header file will be called orangeShuttle.h. Inside this header file will be a reference to the data in the .o, named orangeShuttleTiles and orangeShuttlePal or orangeShuttleBitmap, depending on how the grit file specifies which format to convert your image into. It will also include the length in bytes of the data references as orangeShuttleTilesLen and orangeShuttlePalLen or orangeShuttleBitmapLen.
For our project, we’ll be putting the our graphic files and grit rule files into the gfx directory and having the makefile use grit on them.
Jeśli teraz nie rozumiecie, to po rzuceniu okiem na kod wszystko się wyjaśni.
Otrzymany obrazek .png koniecznie konwertujemy na .bmp z 4 lub 8 bitową głębią kolorów, dowolnym narzędziem, ja wykorzystałem to:
Trzeba dodać ważną rzecz – jak wrzucić font w formacie bmp, aby zawierał przeźroczyste obszary tzn. znak/cyfra na przeźroczystym tle (format bmp nie wspiera kanału alfa – przeźroczystości)?
Wybieramy kolor który nie pojawia się w czionce (piksele o tym kolorze będą interpretowane jako przeźroczystość), sprawdzamy jego wartość w hexach i wrzucamy do pliku grit z przykładu. Przykład z docsów grit:
NDS 16bpp bitmap, with cyan as transparent color
-gb -gB16 -gT 00FFFF
Dopisuję odpowiednią flagę wraz z wartością (209c00) i edytuję spritesheet w gimpie, zmieniając tło znaków/liter/cyfr na zielony #209C00:
Zerknijmy teraz na kod który wypisze nasz tekst na ekran ds-a:
Tutaj jak wspomniałem wcześniej, przydaje się znajomość od którego znaku ASCII zaczynamy nasz spritesheet (linia z font.asciiOffset = 32).
W powyższym kodzie pojawia się kilka makr i funkcji biblioteki nds, nie ma co przedstawiać ich tutaj wybiórczo bo potrzebny jest do tego trochę pełniejszy obraz który można znaleźć w wymienionych wcześniej tutorialach.
Całość kompilujemy i włączamy emulatorem:
Koniec części 1.
Inne
Konfiguracja ndslib pozwalająca jednocześnie wypisywać konsolę + rysować sprite-y:
Onion to de facto router, za 45 zł, z gpio i przerobionym przez producenta openwrt. Rozmiary + cena oniona przewraca mój świat do góry nogami.
Żeby pokazać jakie to jest maleństwo zestawiłem od lewej:
Onion, Arduino micro, Arduino uno, Orange PI one, Raspberry Pi 3.
~
Schemat zabawy:
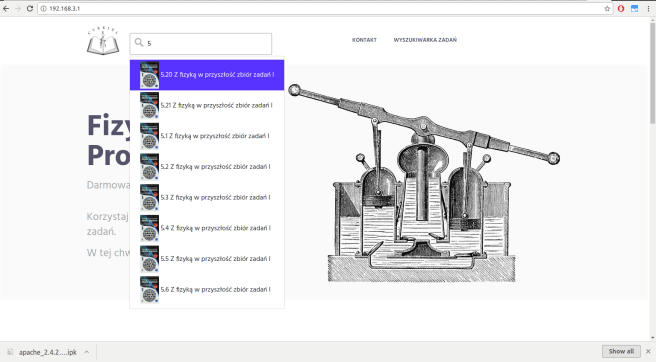
Stawiamy na onionie serwer http (uhttpd) hostujący angularową stronę, którą można podejrzeć na http://www.c-y-r-k-i-e-l.pl (ta jest akurat hostowana na prawdziwych serwerach)
Instalujemy htop
Testujemy obciążenie przez jmeter
Przygotowania
Plus i minus jest na dwóch pierwszych pinach od strony z wcięciem.
Absurdem jest, że rozszerzenie do zasilania oniona po usb kosztuje więcej niż sam onion. Całe szczęście mamy zasilacz renomowanej chińskiej marki (sugestywna cisza)…
Onion przyjmuje 3.3 V, lepiej nie ustawiajcie 3.5 V jeśli wierzycie temu co wskazuje wasz zasilacz.
Radiator, model π-FF-KO, wariant 500ML
Celowo pomijam etap konfiguracji, przechodzenie go przez przewodnik hostowany przez oniona w jego sieci to droga przez mękę, polecam od razu połączyć się przez ssh na root@192.168.3.1 (hasło onioneer), skonfigurować dostęp oniona do internetu przez inną sieć wifi poleceniem wifisetup, wykonać polecenie oupgrade, poczekać parę minut na ściągnięcie i flashowanie nowym firmwarem i zacząć się bawić.
Stawiamy stronę
Defaultowo praktycznie cała pamięć jest zaalokowana na pliki tymczasowe.
Nie mam wspomnianego rozszerzenia usb żeby wypalić własny obraz na onionie, więc improwizuję i wrzucam stronę do /tmp/www (taaak, zniknie po rebootcie) i edytuję /etc/config/uhttpd (uhttpd jest zainstalowany defaultowo, do hostowania wizarda).
Edytuję tylko jedną linię:
Po tym zostaje faktycznie wrzucić stronę w to miejsce:
…i zrestartować serwer:
Po paru chwilach można spróbować wejść na stronę:
HTTP z zapytaniem o zadania nadal trafia do domeny c-y-r-k-ie-l.pl, ale chcę w przyszłości postawić na onionie jakiś mikro serwer z bazą. Tak czy inaczej, można odwiedzić cyrkiel z oniona.
Instalujemy htop
Z niezrozumiałych dla mnie powodów, defaultowe repozytoria jakie są dodane (onionowe, od producenta) nie mają htopa, ale w manualu wskazują jak dodać repo od oryginalnego open-wrt.
Wystarczy więc dodać na koniec pliku /etc/opkg.conf linię:
Dalej zostaje wykonać opkg update, potem opkg install htop i włączyć htopa:
Htop przyda nam się do następnego punktu.
Testujemy obciążenie przez jmeter
Jmeter można pobrać bezpośrednio ze strony Apache (i ten sposób polecam, wcześniej pobrałem przez apt, brakowało template-ów które przydały mi się potem).
Otworzyłem szablon do testowania webserwisów i zmieniłem opcje tak, żeby jmeter pobierał wyłącznie stronę główną + wszystkie powiązane pliki.
Test zaczynam od 20 wątków, ramp-up period to czas w jakim wszystkie mają wystartować (5s/20, jeden wątek musi być tworzony co 250 ms żeby wypełnić podany ramp-up). Onion w prawym górnym rogu, jeszcze niczego się nie spodziewa. START.
Onion w maximum wykorzystania zasobów w trakcie testu, 67 % CPU, średnio 45-55%, max natężenie prądu 0.33 A (w bezczynności oscyluje wokół ~0.17A), cały test trwał mniej niż minutę.
Poradził sobie z 20 wątkami, czemu nie ustawić więc 40?
Tu po raz pierwszy pojawia się na chwilę myśl – obciążenie CPU pozostało takie samo, być może nie uda mi się zagotować Oniona takimi testami, bo standard 802.11 jest bottleneckiem?
Rzucam okiem w docsy: onion wspiera b/g/n, Thinkpad T430 a/b/g/n, jakie szybkości oferuje n?
Wystarczające żeby przesyłać 75 MB na sekundę max, a minimum 12.5 MB, ergo to nie standard jest problemem tylko karta sieciowa na onionie – przetwarza pakiety na tyle wolno, że kernel zwyczajnie nie dostanie aż tyle pakietów do obsłużenia żeby zapełnić go na 100%!
Do ostatecznego dowodu ustawiam z 40 na 1000 wątków z ramp-up na 1s. Loop-count na 200, tak, aby test trwał minimum kilkanaście minut.
Start. Wynik – obciążenie zarówno w pierwszej, w drugiej, dziesiątej i następnych minutach nie przekracza 65 %.
W prawym górnym rogu znajduje się licznik aktywnych wątków wykonujących test.
Wniosek:
1) Nie upieczesz oniona przez ddos
2) Jak bardzo się postarasz i upieczesz to masz nowego za 45 zł
Edit:
Nie potwierdziłem nigdzie, że faktycznie podłączyłem się do 802.11 w wersji ‘n’, post można uzupełnić tym linkiem:
Implementując szkolne mnożenie pisemne nie da się rozwiązać tego zadania w czasie oczekiwanym przez spoj, nawet stosując obliczone wcześniej tablice modulo i mnożenia (próbowałem!).
Tutaj nie ma sensu wymyślanie własnego alogorytmu, conajwyżej można napisać własną implementację jednego z najszybszych znanych algorytmów:
Zadanie trzeba było rozwiązać zauważając powtarzalność ostatniej cyfry potęgowanej liczby, zwykłe potęgowanie byłoby zbyt złożone obliczeniowo dla podanego zestawu.
Jak zauważyć powtarzalność? Kartka papieru, rozpisać ostatnie cyfry dla 0^1, 0^2, …., 1^1, 1^2, 1^3, …, 9^5 itd.
Potem zapisać odpowiednią tabelę w kodzie, tak aby program sięgał jedynie po odpowiednią wartość z tabeli, zamiast obliczać.
To jak długo wykonuje się progam można sprawdzić pod linuxem za pomocą polecenia ‘time’, np. ‘time wget google.com’, jeśli ktoś chce porównać zwykłą implementację z tą z opisanym chwytem.
Można tu jeszcze użyć stdlib lub wyłączyć synchronizację io w iostream, ale to drobiazgi.
Kod:
#include <iostream>using namespace std;int main() { unsigned short results[10][1][4] = {{{0}},{{1}},{{6,2,4,8}},{{1,3,9,7}},{{6,4}},{{5}},{{6}},{{1,7,9,3}},{{6,8,4,2}},{{1,9}},}; unsigned short modulo[] = {1, 1, 4, 4, 2}; long n; cin >> n; long cases[n][2]; for (long a = 0; a < n; a++) cin >> cases[a][0] >> cases[a][1]; for (long a = 0; a < n; a++) { unsigned short moduloDivisorIndex = (cases[a][0] % 5); unsigned short moduloDivisor = modulo[moduloDivisorIndex]; unsigned short lastDigit = cases[a][0] % 10; long moduloIndex = cases[a][1] % moduloDivisor; cout << results[lastDigit][0][moduloIndex] << '\n'; } cout << endl; return 0;}
Zapowiedzianego w ostatnim poście pierwszego próbnego gameplayu nie będzie:
Pomimu kilku prób, mój ThinkPad nie potrafił wydusić z siebie wystarczająco głośnego dźwięku, aby drugi komputer mógł go z powodzeniem odczytać, kończyło się tak, że transmisja była dobra, pomijając w kilku miejsach źle przesłaną cyfrę, co jeśli chodzi o znaki ASCII kończyło się wstawieniem np. znaku pi zamiast dwukropka i w efekcie złym sparsowaniem jsona (modem jest na tyle dobry, że praktycznie zawsze nadawca podsłuchując to co wysyła potrafi to z powrotem sparsować, więc kwestią zostaje głośność).
Prawdopodobnie mógłbym to rozwiązać mikrofonami kierunkowymi, chociaż pozostałby niesmak, że to już nie jest tym, czym było w zamierzeniach (transmisja z urządzenia na urządzenie, bez internetu i specjalnych przyrządów).
Tak czy inaczej, projekt będzie kontynuowany, mam zamiar zakupić pierwszy lepszy kierunkowy mikrofon x2 i nagrać jakiś film, a na ten moment szukam innego wyjścia, w końcu ktoś już napisał podobne aplikacje:
Możliwe, że to kwestia zejścia poziom niżej i napisania własnego wykrywania częstotliwości na podstawie DFT, co nie byłoby takie złe.
W weekend powinien pojawić się nowy post, bo nie sądzę, żebym trafił na ścianę nie do przejścia.
Jak już wspominałem przy okazji posta z serii Pokaż kod, pisząc Speechlist, na początku byłem nastawiony na rozwiązywanie testów głosem. Częściowo mi się to udało, chociaż przeniesienie tego na telefon nie było łatwe, żeby nie powiedzieć – sprawiało kłopoty, dlatego finalnie je porzuciłem na rzecz zwykłego wstawiania tekstu dotykiem. Zostałem z częściowo już napisanym frontendem pod rozpoznawanie głosu, możecie go zobaczyć w działaniu tutaj:
Nie rozpisałem się wtedy co do samego Sphinxa, a to jest temat na większy post.
Czym jest CMUSphinx
CMUSphinx jest opensourcowym narzędziem do rozpoznawania mowy, wspierające C, C++, C#, Python, Ruby, Java, Javascript i rozpoznające m.in. angielski, francuski i niemiecki (chociaż społeczność zbudowała modele rozpoznające także chociażby rosyjski, lista modeli do pobrania jest tutaj).
Wielkim plusem w stosunku chociażby do androidowych usług rozpoznawnia głosu (komunikujących się z serwerami Google) z których można korzystać pisząc aplikacje jest to, że Sphinx działa całkowicie offline.
Do jego działania potrzebne są 3 pliki: acoustic model, dictionary i language model.
Acoustic model zależy od języka i sami go raczej nie stworzymy, pobieramy gotowy z listy którą zamieściłem wyżej. Przykładowo, dla języka angielskiego pobieramy model en-us.
Language model i dictionary generujemy sami za pomocą narzędzi do których odniosę się później, ale można je także pobrać.
Teraz najważniejsze: aby uzyskać niemal 100% skuteczność rozpoznawania, jak na filmiku wyżej, nie używałem gotowego słownika i modelu językowego z ich strony (zawierającego wszystkie słowa). CMUSphinx udostępnia narzędzie, pozwalające zbudować słownik tylko konkretnych słów:
Dzięki temu, że zamieściłem tam tylko te słowa, które muszą być rozpoznane w Speechlistowym teście, poprawność była tak dobra, że trudno uwierzyć.
Przy tym wszystkim warto też dodać, jak niewiele zasobów wymaga Sphinx. Słowniki i modele ważą tyle co nic, a działanie nie wymaga dużej mocy od komputera.
PocketSphinx z którego korzystam na filmiku i w kodzie poniżej, waży 6.7 kB!
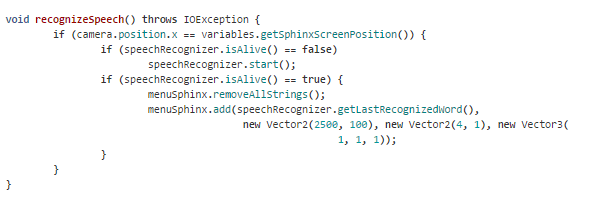
Wykorzystanie Sphinxa w przykładzie z filmiku wygląda następująco:
Tworzymy obiekt edu.cmu.sphinx.api.Configuration, aby załadować z plików modele i słowniki.
Tworzymy obiekt edu.cmu.sphinx.api.LiveSpeechRecognizer, dostarczamy mu konfigurację w konstruktorze i stawiamy warunek który skończy rozpoznawanie mowy (np. while(!lastRecognizedWord.equals(“apple“)), w poniższym przykładzie rozpoznawanie trwa przez cały czas (while(true)).
To wszystko. Teraz, we frontendowej części kodu odczytujemy zapisane przez Sphinx słowa i wyświetlamy na ekranie:
There is no need to remove unused words from the dictionary unless you want to save memory, extra words in the dictionary do not affect accuracy.
Z moich doświadczeń wynika, że jest zupełnie odwrotnie. Przekonajcie się sami, zapiszcie sobie kilka słów na kartce, które chcecie wypróbować na Sphinxie, pobierzcie cały słownik z ich strony, wypróbujcie dokładność, a potem zróbcie to samo generując własny za pomocą ich narzędzia, ale wstawiając do niego tylko te słowa, które potem będziecie wymawiać.





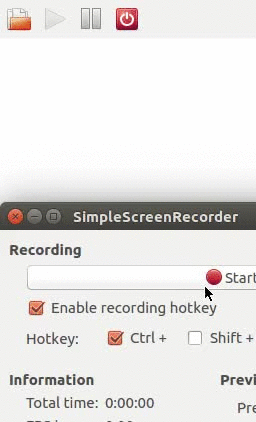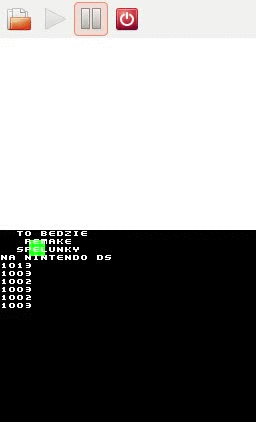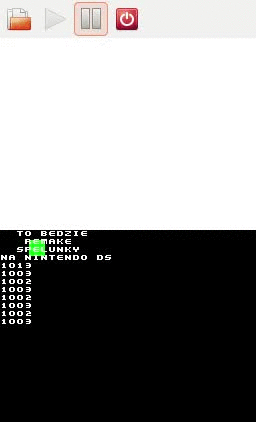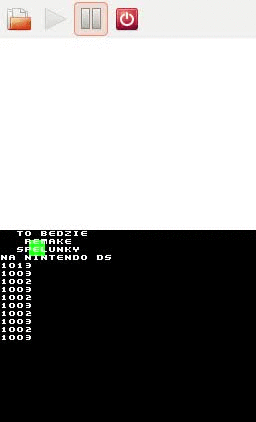
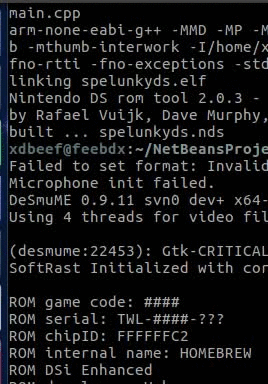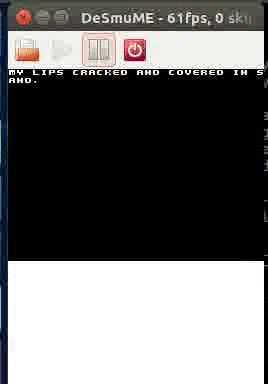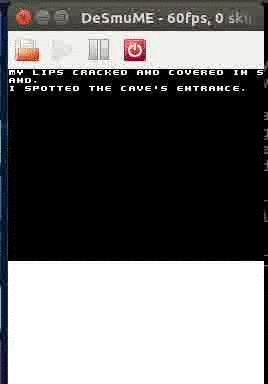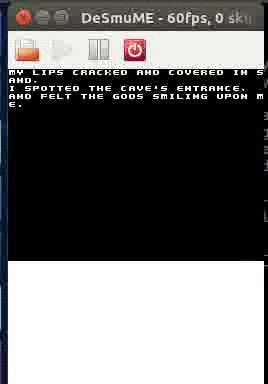
 Screen z intra Spelunky
Screen z intra Spelunky

















 Onion, Arduino micro, Arduino uno, Orange PI one, Raspberry Pi 3.
Onion, Arduino micro, Arduino uno, Orange PI one, Raspberry Pi 3.
 Onion przyjmuje 3.3 V, lepiej nie ustawiajcie 3.5 V jeśli wierzycie temu co wskazuje wasz zasilacz.
Onion przyjmuje 3.3 V, lepiej nie ustawiajcie 3.5 V jeśli wierzycie temu co wskazuje wasz zasilacz. Radiator, model π-FF-KO, wariant 500ML
Radiator, model π-FF-KO, wariant 500ML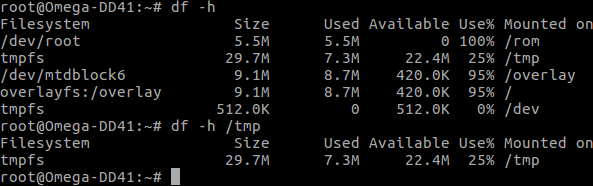



 Test zaczynam od 20 wątków, ramp-up period to czas w jakim wszystkie mają wystartować (5s/20, jeden wątek musi być tworzony co 250 ms żeby wypełnić podany ramp-up). Onion w prawym górnym rogu, jeszcze niczego się nie spodziewa. START.
Test zaczynam od 20 wątków, ramp-up period to czas w jakim wszystkie mają wystartować (5s/20, jeden wątek musi być tworzony co 250 ms żeby wypełnić podany ramp-up). Onion w prawym górnym rogu, jeszcze niczego się nie spodziewa. START. Onion w maximum wykorzystania zasobów w trakcie testu, 67 % CPU, średnio 45-55%, max natężenie prądu 0.33 A (w bezczynności oscyluje wokół ~0.17A), cały test trwał mniej niż minutę.
Onion w maximum wykorzystania zasobów w trakcie testu, 67 % CPU, średnio 45-55%, max natężenie prądu 0.33 A (w bezczynności oscyluje wokół ~0.17A), cały test trwał mniej niż minutę.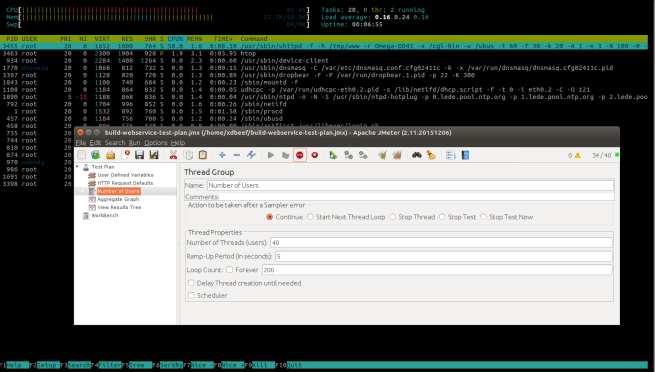


 W prawym górnym rogu znajduje się licznik aktywnych wątków wykonujących test.
W prawym górnym rogu znajduje się licznik aktywnych wątków wykonujących test.



You must be logged in to post a comment.